Benchmarking disk or file system IO performance can be tricky at best. The problem is that modern file systems leverage various techniques to ensure that the best performance is achieved such as caching files in RAM. This means that unless you circumvent the disk cache, your reported speeds will be reporting how quickly the files can be read from memory.
In this example, I’ll cover benchmarking a Linux file system using two methods; dd for the easy route, and bonnie++ for a more comprehensive test.
dd
Write
You can use dd to create a large file as quickly as possible to see how long it takes. It’s a very basic test and not very customisable however it will give you a sense of the performance of the file system. You must make sure this file is larger than the amount of RAM you have on your system to avoid the whole file being cached in memory.
It’s usually installed out-of-the-box with most Linux file systems which makes it an ideal tool in locked-down environments or environments where it’s tricky to get packages installed onto. Use the below command substituting [PATH] with the filesystem path to test, [BLOCK_SIZE] with the block size and [LOOPS] for the amount of blocks to write.
time sh -c "dd if=/dev/zero of=[PATH] bs=[BLOCK_SIZE]k count=[LOOPS] && sync"
A break down of the command is as follows:
- time – times the overall process from start to finish
- of= this is the path which you would like to test. The path must be read/ writable.
- bs= is the block size to use. If you have a specific load which you are testing for, make this value mirror the write size which you would expect.
- sync – forces the process to write the entire file to disk before completing. Note, that dd will return before completing but the time command will not, therefore the time output will include the sync to disk.
The below example uses a 4K block size and loops 2000000 times. The resulting write size will be around 7.6GB.
time sh -c "dd if=/dev/zero of=/mnt/mount1/test.tmp bs=4k count=2000000 && sync"
2000000+0 records in
2000000+0 records out
8192000000 bytes transferred in 159.062003 secs (51501929 bytes/sec)
real 2m41.618s
user 0m0.630s
sys 0m14.998s
Now, let’s do the math. dd tells us how many bytes were written, and the time command tells us how long it took – use the real output at the bottom of the output. Use the formula BYTES / SECONDS. For these larger tests, convert bytes to KB or MB to make more sensible numbers.
(8192000000 / 1024 / 1024) / ((2 * 60) + 41.618)
Bytes converted to MB / (2 minutes + 41.618 seconds)
This gives us an average of 48.34 megabytes per second over the duration of the test.
Read
We can also use dd to test the read speed of a disk by reading the file we created and timing the process. Before we do that, we need to flush the file cache by writing another file which is about the size of the RAM installed on the test system. If we don’t do this, the file we just created will be partially in RAM and therefore the read test will not be completely read from disk.
Create a file using dd which is about the same size as the RAM installed on the system. The below assumes 2GB of RAM is installed. You can check how much RAM is installed with free.
dd if=/dev/zero of=/mnt/mount1/clearcache.tmp bs=4k count=524288
Now for the read test of our original file.
time sh -c "dd if=/mnt/mount1/test.tmp of=/dev/null bs=4k"
And process the time result the same was as when writing.
Bonnie++
Bonnie++ is a small utility with the purpose of benchmarking file system IO performance. It’s commonly available in Linux repositories or available from source from the home page.
On Debian/ Ubuntu based systems, use the apt-get command.
apt-get install bonnie++
Just like with DD, we need to minimise the effect of file caching and therefore the tests should be performed on datasets larger than the amount of RAM you have on the test system. Some people suggest that you should use datasets up to 20 times the amount of RAM, others suggest twice the amount of RAM. Whichever you use, always use the same dataset size for all tests performed to ensure the results are comparable.
There are many commands which can be used with bonnie++, too many to cover here so let’s look at some of the common ones.
- -d – is used to specify the file system directory to use to benchmark.
- -u – is used to run a a particular user. This is best used if you run the program as root. This is the UID or the name.
- -g – is used to run as a particular group. This is the GID or the name.
- -r – is used to specify the amount of RAM in MB the system has installed. This is total RAM, and not free RAM. Use free -m to find out how much RAM is on your system.
- -b – removes write buffering and performs a sync at the end of each bonnie++ operation.
- -s – specifies the dataset size to use for the IO test in MB.
- -n – is the number of files to use for the create files test.
- -m – this adds a label to the output so that you can understand what the test was at a later date.
- -x n – is used to repeat the tests n times. Change n to the number of how many times to run the tests.
bonnie++ performs multiple tests, depending on the arguments used, and does not display much until the tests are complete. When the tests complete, two outputs are visible. The bottom line is not readable (unless you really know what you are doing) however above that is a table based output of the results of the tests performed.
Let’s start with a basic test, telling bonnie++ where to test and how much RAM is installed, 2GB in this example. bonnie++ will then use a dataset twice the size of the RAM for tests. As I am running as root, I am specifying a user name.
bonnie++ -d /tmp -r 2048 -u james
bonnie++ will take a few minutes, depending on the speed of your disks and return with something similar to the output below.
Using uid:1000, gid:1000.
Writing a byte at a time...done
Writing intelligently...done
Rewriting...done
Reading a byte at a time...done
Reading intelligently...done
start 'em...done...done...done...done...done...
Create files in sequential order...done.
Stat files in sequential order...done.
Delete files in sequential order...done.
Create files in random order...done.
Stat files in random order...done.
Delete files in random order...done.
Version 1.96 ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
ubuntu 4G 786 99 17094 3 15431 3 4662 91 37881 4 548.4 17
Latency 16569us 15704ms 2485ms 51815us 491ms 261ms
Version 1.96 ------Sequential Create------ --------Random Create--------
ubuntu -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 142 0 +++++ +++ +++++ +++ +++++ +++ +++++ +++ +++++ +++
Latency 291us 400us 710us 382us 42us 787us
1.96,1.96,ubuntu,1,1378913658,4G,,786,99,17094,3,15431,3,4662,91,37881,4,548.4,17,16,,,,,142,0,+++++,+++,+++++,+++,+++++,+++,+++++,+++,+++++,+++,16569us,15704ms,2485ms,51815us,491ms,261ms,291us,400us,710us,382us,42us,787us
The output shows quite a few statistics, but it’s actually quite straight forward once you understand the format. First, discard the bottom line (or three lines in the above output) as this is the results separated by a comma. Some scripts and graphing applications understand these results but it’s not so easy for humans. The top few lines are just the tests which bonnie++ performs and again, can be discarded.
Of cause, all the output of bonnie++ is useful in some context however we are just going to concentrate on random read/ write, reading a block and writing a block. This boils down to this section:
Version 1.96 ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
ubuntu 4G 786 99 17094 3 15431 3 4662 91 37881 4 548.4 17
Latency 16569us 15704ms 2485ms 51815us 491ms 261ms
The above output is not the easiest output to understand due to the character spacing but you should be able to follow it, just. The below points are what we are interested in, for this example, and should give you a basic understanding of what to look for and why.
- ubuntu is the machine name. If you specified -m some_test_info this would change to some_test_info.
- 4GB is the total size of the dataset. As we didn’t specify -s, a default of RAM x 2 is used.
- 17094 shows the speed in KB/s which the dataset was written. This, and the next three points are all sequential reads – that is reading more than one data block.
- 15431 is the speed at which a file is read and then written and flushed to the disk.
- 37881 is the speed the dataset is read.
- 548.4 shows the number of blocks which bonnie++ can seek to per second.
- Latency number correspond with the above operations – this is the full round-trip time it takes for bonnie++ to perform the operations.
Anything showing multiple +++ is because the test could not be ran with reasonable assurance on the results because they completed too quickly. Increase -n to use more files in the operation and see the results.
bonnie++ can do much more and, even out of the box, show much more but this will give you some basic figures to understand and compare. Remember, always perform tests on datasets larger than the RAM you have installed, multiple times over the day, to reduce the chance of other processes interfering with the results.
 ZFS is a disk and logical volume manager combining raid like functionality with guaranteeing data integrity. Every block of data read by ZFS is checksumed and recovered if an error is found. ZFS also periodically checks the entire file system for any silent corruption which may have occurred since the data was written.
ZFS is a disk and logical volume manager combining raid like functionality with guaranteeing data integrity. Every block of data read by ZFS is checksumed and recovered if an error is found. ZFS also periodically checks the entire file system for any silent corruption which may have occurred since the data was written.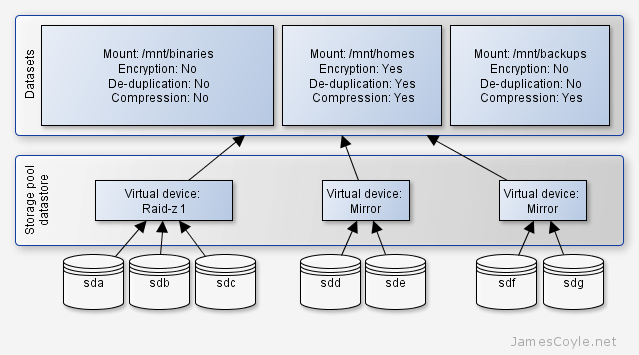
 If you can, your storage servers should be in a secure zone in your network removing the need to firewall each machine. Inspecting packets incurs an overhead, not something you need on a high performance file server so you should not run a file server in an insecure zone. If you are using GlusterFS behind a firewall you will need to allow several ports for GlusterFS to communicate with clients and other servers. The following ports are all TCP:
If you can, your storage servers should be in a secure zone in your network removing the need to firewall each machine. Inspecting packets incurs an overhead, not something you need on a high performance file server so you should not run a file server in an insecure zone. If you are using GlusterFS behind a firewall you will need to allow several ports for GlusterFS to communicate with clients and other servers. The following ports are all TCP: