Parallel Replication In MariaDB
Category : How-to
Parallel replication has been available in MariaDB since Version 10.0.5, however requires at least version 10.0.5 on both the Master and Slave for parallel replication to work.
Parallel replication can help speed up applying changes to a MariaDB slave server by applying several changes at once.
What is Parallel Replication?
MariaDB replicates data from a master to a slave by shipping all changes that have been applied to the master to the slave in a serialised file. The file is then read by the slave and each change is applied one at a time. A change may be a single row change, such as an INSERT, a DDL change or statement that is applied in it’s entirety such as INSERT INTO… SELECT. The bottle neck to this process is that the changes which need to be applied are read in serial – that is, one at a time.
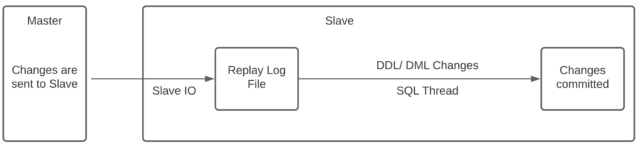
Parallel replication tries to overcome this by applying DML statements in parallel by reading ahead in the relay log (the log on the slave with changes waiting to be applied) and giving work to each parallel worker to apply, in parallel! Each parallel worker has a cache that allows it to read ahead in the log and apply statements that can be applied in parallel – these are usually statements applied in a single transaction, or statements that have been committed in the same group.
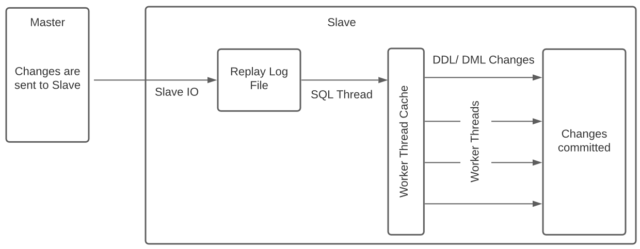
The above diagrams show the differences between the different replication mode. Up to the SQL Thread things work in much the same way, however in parallel replication mode the SQL Thread behaves differently in that it moves work to the Worker threads rather than applying it directly itself.
Enable Parallel Replication
You will need MariaDB 10.0.5 or later running on both the master and the slave for parallel replication to be available.
Edit your MariaDB config file, my.cnf on some installations and edit or add the following parameter.
slave-parallel-threads=12This will enable 12 parallel workers on the database Slave which will be started when your slave server is next restarted and replication is enabled.
You can see if the required number of workers has been started by running show processlist which will show 12 processes running as system user with various State information.
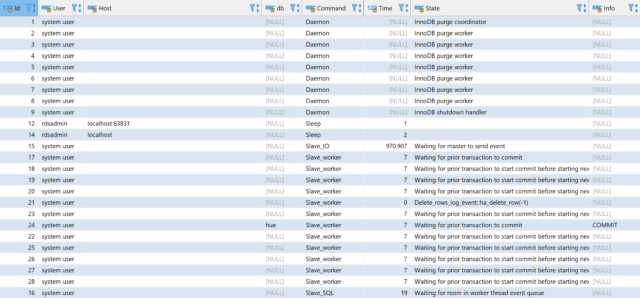
You can see further information by running show slave status which will show you the replication type, how up to date the replication is and if there are any errors.